Modèles d'intégration Snowflake vers NetSuite pour la planification et l'analyse financière (FP&A)
Intégration de Snowflake à NetSuite pour le FP&A : Synchronisation NSAW, requêtes directes et modèles de Reverse-ETL
Résumé analytique
Les fonctions modernes de Planification et Analyse Financière (FP&A) exigent de plus en plus une intégration transparente entre les systèmes d'entreprise (comme Oracle NetSuite ERP) et les plateformes d'analyse haute performance (comme Snowflake). Ce rapport examine les modèles d'intégration Snowflake–NetSuite pertinents pour le FP&A, en se concentrant sur trois paradigmes : la synchronisation NSAW ( NetSuite Analytics Warehouse chargement de données), les approches par requête directe et les flux de Reverse-ETL. Nous analysons les pratiques historiques et actuelles, comparons les architectures et les outils, et citons des données et des exemples de cas. Les conclusions clés indiquent que les organisations adoptent couramment des pipelines ETL natifs du cloud (ex. Fivetran, Airbyte) pour répliquer NetSuite dans Snowflake à des fins d'analyse [1], que l'accès natif via SuiteAnalytics Connect (ODBC/JDBC) s'avère souvent insuffisant à grande échelle [2], et que les équipes FP&A exploitent de plus en plus des outils de reverse-ETL (Census, Fivetran Activations, etc.) pour synchroniser les résultats analytiques vers NetSuite selon les besoins [3] [4]. Nous proposons une discussion détaillée sur les capacités analytiques de NetSuite (NSAW), les compromis de performance (temps réel vs traitement par lots) et les tendances émergentes (analyse pilotée par l'IA, automatisation des entrepôts de données, normes d'intégration). De multiples études de cas (de BirdRock Brands et Overture Promotions utilisant NSAW [5] [6] à une implémentation Fivetran chez GitLab [7]) illustrent les avantages et les pièges. Enfin, nous évaluons les implications pour l'agilité du FP&A et esquissons les orientations futures telles qu'une intégration accrue de l'IA/ML et l'évolution des fonctionnalités des plateformes.
Introduction et contexte
Les équipes de Planification et Analyse Financière (FP&A) s'appuient sur des données intégrées provenant des systèmes ERP, CRM, marketing et opérationnels pour préparer les prévisions, les budgets et les rapports de gestion. Dans de nombreuses organisations, NetSuite sert de système d'enregistrement pour la finance, générant des données transactionnelles à haut volume. Cependant, le reporting natif de NetSuite est souvent limité en termes d'échelle et de fonctionnalité – les analystes du secteur notent que les plateformes ERP d'entreprise rendent fréquemment le reporting « extrêmement complexe » et laissent les dirigeants « lutter pour extraire des informations exploitables » à partir des données financières [8]. Par conséquent, une architecture de stack de données moderne a émergé : les données transactionnelles de base sont déchargées vers une plateforme d'analyse spécialisée (comme Snowflake) via des pipelines d'intégration, permettant un ETL évolutif, l'intégration avec d'autres sources de données et des outils BI/ML puissants [9] [10].
Snowflake est un entrepôt de données cloud de premier plan qui prend en charge le calcul élastique, la haute concurrence et le déploiement multi-cloud. Les organisations choisissent Snowflake comme hub analytique, consolidant les données ERP (entre autres) pour prendre en charge les tableaux de bord, la consolidation financière et l'analyse avancée [1]. NetSuite, désormais partie d'Oracle, offre diverses voies pour accéder aux données : les recherches enregistrées intégrées et SuiteAnalytics (l'interface ODBC/JDBC de NetSuite), mais aussi un NetSuite Analytics Warehouse (NSAW) – une offre d'entrepôt de données géré qui synchronise automatiquement les données ERP (et d'autres sources) dans un modèle consolidé construit sur Snowflake/Oracle Autonomous Data Warehouse [11]. Comprendre comment Snowflake et NetSuite (et NSAW) interagissent est essentiel pour la modernisation du FP&A.
Ce rapport couvre le contexte historique (ex. exportations par lots traditionnelles et data marts sur site), l'état actuel (ETL cloud, reverse-ETL, outils de requête directe) et les perspectives d'avenir (analyse infusée par l'IA, planification continue). Nous étudions les modèles d'intégration (décrits ci-dessous), analysons les compromis en matière de performance et de qualité des données, citons la documentation des fournisseurs et les rapports d'analystes, et incluons des perspectives quantitatives lorsque disponibles. L'objectif est de fournir un guide technique et stratégique complet pour les planificateurs d'entreprise et les architectes de données.
Reporting traditionnel vs Analyse moderne
Historiquement, le FP&A s'appuyait sur des exportations périodiques (ex. extraits CSV) ou un ETL personnalisé pour déplacer les données ERP vers un data mart sur site. Ces méthodes souffraient de latence et de charges manuelles. Avec l'ERP cloud et l'entreposage, les modèles d'intégration en temps réel ont évolué. Par exemple, les consultants observent que les API de NetSuite sont « notoirement compliquées » et que les vues propriétaires limitent l'analyse directe dans l'ERP lui-même [2]. En revanche, les entrepôts de données conçus à cet effet permettent aux équipes FP&A de combiner les données NetSuite avec d'autres sources (CRM des ventes, paie, etc.) dans un modèle cohérent [1] [12]. Comme le note un blog du secteur, « À mesure que votre entreprise grandit... la latence du reporting devient plus difficile à ignorer », ce qui motive le passage à l'entreposage cloud et aux outils BI [13].
Parallèlement, Oracle a investi dans les services d'analyse : NetSuite Analytics Warehouse (NSAW) est présenté comme un entrepôt de données pré-construit et activé par l'IA pour les clients NetSuite [14]. NSAW fournit des analyses intégrées, des rafraîchissements plus fréquents et des informations assistées par l'IA (ex. détection d'anomalies, prévisions) directement liées aux données ERP [15] [16]. NSAW peut ingérer des données externes (voir ci-dessous) et alimenter des tableaux de bord visuels, réduisant ainsi le basculement entre les applications. Ces développements coïncident avec une tendance plus large du marché ; les rapports soulignent que le marché de l'entreposage de données cloud devrait presque doubler (à ~70 milliards de dollars) dans les prochaines années [17], et que d'ici 2026, jusqu'à 80 % des charges de travail analytiques intégreront l'IA/ML [18]. Cela souligne l'impératif stratégique pour les DAF d'exploiter des analyses intégrées basées sur le cloud pour une prise de décision opportune [19].
En résumé, les équipes FP&A naviguent aujourd'hui entre plusieurs plateformes. Elles peuvent initier des analyses dans NetSuite (via SuiteAnalytics), dans Snowflake (via des données répliquées) ou en partie dans NSAW. Le choix du bon modèle d'intégration dépend des exigences en matière de fraîcheur, d'exhaustivité et de facilité d'utilisation. Les sections suivantes approfondissent trois modèles clés : Synchronisation NSAW, Requête directe et Reverse-ETL.
NetSuite Analytics Warehouse (NSAW) et intégration Snowflake
Présentation de NSAW
Le NetSuite Analytics Warehouse (NSAW) d'Oracle est une offre d'entrepôt de données SaaS géré pour les clients NetSuite [14]. Construit sur la technologie d'entrepôt de données cloud d'Oracle (Autonomous Data Warehouse) et intégrant l'IA, NSAW consolide automatiquement les données transactionnelles ERP d'une entreprise (sur toutes les filiales et périodes) et permet aux utilisateurs d'exécuter des analyses avancées sur des modèles de données métier pré-construits. Les fonctionnalités clés incluent des tableaux de bord intégrés dans l'interface utilisateur NetSuite, des domaines financiers multidimensionnels rafraîchis (GL, P&L, Bilan, etc.) et des informations pilotées par l'IA comme la prévision prédictive et les alertes d'anomalies [15] [20]. NSAW abstrait également de nombreuses tâches d'ingénierie de données : Oracle met régulièrement à jour les schémas (« tableaux de bord détaillés » pour les nouveaux modules) et propose des analyses guidées sans obliger les clients à construire des modèles de données à partir de zéro [15].
Il est important de noter que NSAW ne se limite pas aux données de NetSuite. Il prend en charge des augmentations de données provenant de sources externes pour améliorer les analyses. La documentation d'Oracle confirme que NSAW inclut un service d'extraction capable de se connecter à une instance Snowflake et de charger ses tables dans l'environnement NSAW [21]. En pratique, un administrateur peut configurer une connexion de données Snowflake au sein de la console NSAW (en spécifiant l'hôte, la base de données, les identifiants, etc.) [21]. Une fois connecté, NSAW peut effectuer une extraction de métadonnées des tables Snowflake choisies, puis utiliser ces tables comme « augmentations de données » au-dessus du schéma NetSuite principal [21] [22]. Cela signifie, par exemple, qu'une entreprise pourrait intégrer des dépenses marketing externes ou des chiffres de vente tiers provenant de Snowflake et les mélanger avec les données financières de NetSuite dans les rapports NSAW. Les documents Oracle précisent les étapes : activer la fonctionnalité Snowflake, créer une connexion Snowflake avec une authentification de base ou basée sur une clé, puis sélectionner les tables sources Snowflake dans l'interface d'augmentation de données de NSAW [21] [23].
Les mises en garde techniques incluent la liste blanche réseau (les IP d'Oracle doivent être autorisées sur Snowflake) [24] et le fait que les données dans Snowflake doivent être mises en staging dans des formats de fichiers pris en charge (CSV, Parquet, etc.) [25]. Une fois configuré, NSAW traite les tables Snowflake importées comme n'importe quelle autre donnée : les tableaux de bord et les mises en page d'écran peuvent afficher des mesures impliquant à la fois NetSuite et des champs provenant de Snowflake. Ce modèle de synchronisation NSAW utilise efficacement NSAW comme plateforme d'analyse centrale, Snowflake agissant comme l'une des nombreuses sources. Dans un contexte FP&A, la synchronisation NSAW pourrait être utilisée pour, par exemple, importer une prévision externe ou un pipeline CRM dans NSAW et le comparer aux données réelles dans NetSuite sans quitter l'environnement NSAW.
Avantages de NSAW pour le FP&A
Du point de vue du FP&A, NSAW offre plusieurs avantages. Son modèle de données financières pré-construit et ses domaines permettent aux analystes de parcourir des mesures standardisées (ex. Book-to-Bill, trésorerie actuelle, rotation des stocks) sans modélisation à partir de tables brutes [15] [20]. Le nouveau domaine budgétaire (présent dans les mises à jour NSAW) prend explicitement en charge l'analyse de scénarios budget vs réel [26]. Les exemples de clients d'Oracle mettent cela en évidence : BirdRock Brands, un détaillant, utilise NSAW pour prévoir la rentabilité et suivre les stocks en mouvement, en tirant parti de ses fonctionnalités d'IA pour des informations basées sur des modèles (le DAF note que NSAW « élève notre intelligence d'affaires » et les aide à « prendre des décisions plus éclairées » [5]). De même, Overture Promotions rapporte que NSAW fournit des « informations prédictives à partir de nos tendances de vente » pour éclairer la planification de la chaîne d'approvisionnement [6]. Ces témoignages suggèrent que NSAW peut unifier les jeux de données FP&A et appliquer l'IA pour améliorer les flux de travail de budgétisation et de prévision.
Un autre avantage est l'expérience utilisateur. NSAW intègre des tableaux de bord directement dans l'interface utilisateur NetSuite, permettant aux DAF de cliquer sur un lien dans leur ERP et de voir instantanément des graphiques qui mélangent les données NetSuite avec tous les jeux de données Snowflake augmentés [15]. Cela réduit les frictions (pas de changement de contexte vers des applications BI externes) et peut accélérer l'adoption de l'analyse dans toute la finance. La planification flexible de NSAW (options de rafraîchissement plus fréquentes) fournit des données plus fraîches ; les clients ont signalé la planification de plusieurs chargements quotidiens au lieu des travaux nocturnes hérités [27]. La sécurité et la gouvernance sont également gérées par Oracle : NSAW respecte les rôles NetSuite pour le contrôle d'accès, de sorte que les utilisateurs FP&A ne voient que les données autorisées (ex. par filiale ou département) [28].
Cependant, NSAW a des limites. Il s'agit d'un module complémentaire sous licence séparée et optimisé pour l'analyse centrée sur NetSuite. Si le FP&A doit intégrer de grands volumes de données provenant de nombreux autres systèmes (ex. sources BigQuery/Snowflake ad-hoc), NSAW seul peut ne pas suffire. La capacité de NSAW à ingérer des données Snowflake via le service d'extraction est précieuse, mais dans de nombreux cas, les organisations exécutent également des pipelines d'analyse Snowflake parallèles indépendants de NSAW. En fait, le propre message d'Oracle positionne NSAW comme complémentaire à une stack de données moderne : certains clients ont signalé à la fois l'utilisation de tableaux de bord NSAW et la réplication de données vers Snowflake pour la BI d'entreprise [1]. L'intégration de Snowflake dans NSAW est encore une fonctionnalité en préversion plus récente [21], et les clients doivent prévoir des tests pilotes. Les architectes FP&A doivent aligner l'utilisation de NSAW avec leur architecture globale – soit en se concentrant sur NSAW, soit sur une instance Snowflake partagée avec NSAW comme l'un des outils de reporting.
La synchronisation NSAW en pratique
En pratique, le modèle de synchronisation NSAW peut se dérouler comme suit : un administrateur financier configure une source de données Snowflake dans NSAW, en mappant une ou plusieurs tables d'intérêt. NSAW charge ensuite ces tables dans sa base de données (sous réserve de la licence autorisant un certain volume de données personnalisées). Une fois chargées, les analystes définissent des augmentations de données (essentiellement des jointures ou des combinaisons) entre le schéma canonique de NetSuite et les nouvelles tables. Par exemple, lier une table « MarketingSpends » stockée dans Snowflake à la dimension filiale de NetSuite permettrait de créer une feuille de calcul combinée montrant les dépenses par rapport aux ventes. Étant donné que NSAW s'appuie sur l'entrepôt de données cloud d'Oracle, la concurrence et les performances sont gérées par le service (bien que les clients doivent surveiller leurs métriques d'utilisation des données personnalisées pour les limites de volume [29]). Le résultat final est un jeu de données analytiques unifié, accessible via les « feuilles de travail » du tableau de bord de NSAW ou par SQL (SuiteAnalytics Connect peut interroger l'entrepôt NSAW si nécessaire).
Selon Oracle, le connecteur Snowflake-vers-NSAW ne nécessite que quelques étapes et fonctionne ensuite selon un calendrier [21] [23]. Le statut « Preview » signifie que les clients doivent se coordonner avec le support Oracle. Comme le note une analyse du secteur, NSAW fournit essentiellement un entrepôt de données SaaS basé sur Snowflake pour les données NetSuite [30]. À cet égard, la fonctionnalité de synchronisation NSAW étend cet entrepôt SaaS pour accepter les données Snowflake de la même manière que les tables externes Snowflake, mais au sein de l'écosystème géré par Oracle. Elle est donc parfaitement adaptée aux équipes FP&A qui souhaitent exploiter les données Snowflake au sein de leur structure analytique NetSuite, sans avoir à créer un pipeline séparé vers, par exemple, BigQuery ou Power BI.
Modèles de requête directe (Direct Query)
SuiteAnalytics Connect (ODBC/JDBC)
Le terme « Direct Query » peut avoir des significations différentes selon le contexte. Dans un sens, il fait référence à la connexion directe d'outils de BI à une source de données pour obtenir des résultats à la minute près (plutôt que de précharger les données). NetSuite propose un produit officiel appelé SuiteAnalytics Connect, qui fournit des pilotes ODBC/JDBC/ADO.NET exposant le modèle de données NetSuite en tant que source accessible par SQL [31] [2]. En théorie, Connect permet à quiconque disposant d'un client SQL (par exemple Excel, SQL Server ou des scripts Python) d'exécuter des requêtes SELECT sur les données ERP en temps réel. Cela peut simplifier le reporting ad hoc pour les petits jeux de données ; on peut, par exemple, faire glisser des tables NetSuite dans un rapport Power BI.
Cependant, en pratique, SuiteAnalytics Connect présente des contraintes importantes. Il est strictement en lecture seule et implémenté via les API de NetSuite. Oracle avertit que les requêtes Connect sont limitées pour protéger le système transactionnel ; par conséquent, les requêtes très volumineuses peuvent être lentes ou même expirer (les explorations de type SAP héritées peuvent ne pas aboutir) [32] [2]. Les consultants signalent que Connect manque de métadonnées complètes sur les clés étrangères, et que Power BI ne peut pas utiliser le mode « DirectQuery » réel avec lui (seul le mode Import est disponible) [33]. Comme l'explique une analyse, étant donné que Connect ne peut pas prendre en charge DirectQuery, les grandes tables doivent être entièrement importées dans la mémoire de l'outil de BI, et les tentatives d'actualisation en direct échouent souvent [33]. Ainsi, Connect est utile pour interroger occasionnellement des tables de taille modérée, mais pas pour le reporting FP&A à l'échelle de l'entreprise.
En raison de ces limitations de Connect, de nombreuses organisations adoptent un modèle hybride de requête directe : utiliser Connect uniquement pour extraire les données vers un autre stockage (comme Snowflake), puis effectuer le reporting sur cette copie. Par exemple, un client bancaire pourrait utiliser la version JDBC de Connect dans un ETL quotidien, puis laisser les analystes créer des tableaux de bord sur Snowflake. Dans ce modèle, une fois les données dans Snowflake, Power BI ou Tableau peuvent se connecter via DirectQuery ou des liens d'entrepôt publiés, permettant une analyse interactive sur de grands volumes de données. En fait, les suites de BI modernes se connectent souvent directement à Snowflake ou similaire, contournant totalement NetSuite au moment du reporting [2] [34]. Nous en discuterons sous peu.
Connexions BI directes vers Snowflake
Une autre signification de Direct Query est simplement la connexion d'outils de BI à Snowflake. Une architecture couramment approuvée par le FP&A est la suivante : SuiteAnalytics Connect ou un ETL charge NetSuite dans Snowflake ; puis les outils de BI (Power BI, Tableau, etc.) se connectent à Snowflake pour le reporting. Lorsque Power BI est sur une capacité Premium ou Fabric, il prend en charge DirectQuery vers Snowflake, ce qui signifie que les requêtes s'exécutent en direct dans Snowflake sans importation préalable des données. Des tableaux de bord en temps réel sont ainsi possibles. HouseBlend et d'autres notent qu'il s'agit d'une capacité clé : par exemple, Power BI Premium utilisant DirectQuery vers Snowflake a permis à un directeur des opérations de vente au détail d'explorer les détails au niveau du magasin à partir d'un total des ventes de l'entreprise en quelques secondes seulement [35], un exploit irréalisable avec les outils intégrés à l'ERP. Cette amélioration de la latence de bout en bout (passant de minutes ou d'heures à quelques secondes) illustre les gains de performance obtenus en laissant Snowflake gérer les requêtes.
Le mode DirectQuery comporte toutefois des mises en garde. Toute la charge de requête impacte la puissance de calcul de Snowflake (entraînant des coûts d'utilisation), et les modèles complexes peuvent être plus lents en DirectQuery qu'en mémoire. Mais pour de nombreuses métriques FP&A (bilans, comptes de résultat consolidés, prévisions), le volume de données et les modèles de filtrage sont gérables. Les outils mettent également en cache les métadonnées et peuvent combiner des modèles d'importation/push pour équilibrer vitesse et coût. L'impact net est que les analystes peuvent explorer des jeux de données beaucoup plus riches. Par exemple, une équipe financière pourrait interroger directement des transactions de vente pluriannuelles jointes à des données de planification sans craindre la limite d'importation de 1 Go de Power BI (le jeu de données résidant dans Snowflake).
En résumé, les modèles de requête directe en FP&A impliquent souvent des connexions BI-vers-Entrepôt plutôt qu'ERP. DirectQuery vers Snowflake (comme ci-dessus) est un modèle. Un autre consiste à utiliser des services de requête externes : Snowflake lui-même prend en charge les « tables externes » et le partage de données, permettant un flux de travail domestique où Snowflake lit les données directement à partir d'une zone de transit externe (par exemple S3 ou source ODBC) sans chargement préalable. Cela pourrait hypothétiquement permettre à Snowflake d'interroger une source ODBC NetSuite en direct. En fait, les offres de la Snowflake Marketplace (voir ci-dessous) exploitent cela : les connecteurs natifs (par exemple Infometry) exécutent efficacement les requêtes SuiteAnalytics à la volée lorsque Snowflake a besoin de nouvelles données [36]. Cela découple également l'étape de chargement, bien qu'en pratique, cela implique toujours des activités d'extraction en arrière-plan.
Requête directe vers NSAW
Une capacité plus récente concerne NSAW : Oracle a annoncé que NSAW peut désormais intégrer des visualisations NSAW dans les tableaux de bord NetSuite [15]. Sous le capot, on pourrait considérer cela comme une « requête directe » à partir d'un contexte NetSuite : un utilisateur clique sur un lien dans NetSuite, et NSAW affiche un graphique basé sur les dernières données de l'entrepôt (y compris les données augmentées par Snowflake). Comme NSAW fonctionne sur une architecture cloud haute performance, il s'agit effectivement d'un exemple de modèle de délestage de requêtes : les requêtes d'ingénierie s'exécutent en dehors de l'ERP, mais les résultats sont présentés en contexte à l'utilisateur FP&A. Cette approche hybride de requête directe / vue intégrée rationalise les flux de travail (pas de basculement entre les applications) tout en évitant les limites de concurrence de NetSuite.
Modèles de Reverse-ETL
Concept et cas d'utilisation
Le « Reverse-ETL » consiste à prendre des données transformées ou dérivées dans un entrepôt de données (Snowflake) et à les renvoyer vers des systèmes opérationnels ou CRM (comme NetSuite). Pour le FP&A, cela peut être moins courant, mais cela se présente dans des scénarios tels que :
- Chargement de budgets/prévisions : Supposons qu'une équipe financière calcule des chiffres budgétaires (à partir de données historiques dans Snowflake, peut-être en utilisant une solution de planification externe) et doive importer ces montants budgétaires dans NetSuite pour l'analyse des écarts ou pour tirer parti du module de budgétisation de NetSuite. Le Reverse-ETL pourrait automatiser l'envoi de ces chiffres dans les dimensions NetSuite (par exemple, budgets départementaux, prévisions).
- Enrichissement des données de référence : Si Snowflake contient des attributs clients (par exemple, scores de crédit, segmentation) issus d'analyses externes, on pourrait synchroniser les champs mis à jour avec les enregistrements CRM de NetSuite pour des vues unifiées.
- Mise à jour des données de référence/prix : Une fonction FP&A pourrait créer des prix personnalisés ou des facteurs d'allocation dans Snowflake ; elle pourrait les renvoyer vers les enregistrements d'articles ou de groupes de NetSuite.
- Métriques glissantes : Les indicateurs de performance clés calculés dans Snowflake (comme les métriques de désabonnement des cohortes) pourraient être poussés dans des champs personnalisés de NetSuite pour le reporting.
Le défi est que NetSuite n'accepte pas nativement les connexions entrantes de Snowflake. Comme le notent les blogs de Census et Fivetran, « NetSuite n'offre aucun type de support natif pour se connecter à Snowflake » [3] [4]. En pratique, deux approches sont utilisées : (1) un pipeline de données manuel (déchargement de Snowflake vers CSV, puis importation dans NetSuite à l'aide de son outil d'importation CSV ou des API SuiteTalk), ou (2) un outil d'automatisation de Reverse-ETL spécialisé qui gère l'envoi.
Reverse-ETL manuel (CSV & API)
Sous sa forme la plus simple, une requête Snowflake (ou COPY INTO @stage) décharge les données au format CSV sur une zone de transit ou un disque local [37]. Ensuite, à l'aide de l'Assistant d'importation CSV de NetSuite, les données sont mappées aux types d'enregistrements NetSuite (Clients, Articles, Transactions, Budgets, etc.) et chargées. La documentation d'Oracle indique que de nombreux enregistrements (variantes, budgets, employés) peuvent être importés via CSV, et les expose même via des points de terminaison REST [38]. Par exemple, les budgets ont un enregistrement REST « Budget Import » [38] accessible pour POST. Cependant, l'importation CSV est souvent une tâche ponctuelle ou par lots nocturnes – elle nécessite généralement une configuration humaine et peut être fragile si les schémas de données changent. Elle s'exécute également sous les files d'attente d'importation de NetSuite (une utilisation excessive de l'importation CSV peut également atteindre les limites de gouvernance).
Alternativement, on peut utiliser les API SuiteTalk SOAP ou REST de NetSuite pour insérer ou mettre à jour des enregistrements par programmation. Un script middleware (ou un connecteur comme Celigo) peut lire Snowflake via ODBC/JDBC, puis appeler les points de terminaison SOAP de NetSuite. C'est plus agile mais nécessite une gestion prudente des limites de 1000 lignes par requête de NetSuite et de l'utilisation de la gouvernance. Des outils comme Celigo (et le désormais obsolète « Celigo integrator.io ») fournissent des modèles pour les flux Snowflake→NetSuite, montrant que ce modèle est viable [39] [40]. Par exemple, la plateforme moderne de Celigo inclut un modèle « Snowflake – NetSuite » qui peut synchroniser les détails des clients ou des commandes de vente de Snowflake vers NetSuite [41]. Cependant, les appels API directs nécessitent de construire les mappages de champs et d'assurer des clés idempotentes, ce qui peut être complexe pour des objets financiers complexes.
Outils de Reverse-ETL et automatisation
Plus récemment, des fournisseurs ont développé des pipelines de Reverse-ETL spécialement conçus pour abstraire la complexité. Census, Hightouch, Fivetran (Activations) et d'autres permettent aux utilisateurs de définir des transformations dans Snowflake, puis de pousser les résultats vers NetSuite. Ces outils prennent généralement en charge NetSuite en tant que destination prête à l'emploi. Par exemple, le guide de Census couvre explicitement la synchronisation Snowflake→NetSuite en utilisant leur plateforme [37]. Fivetran décrit également le flux de travail, notant qu'en l'absence de flux natifs, il faut « exporter et importer manuellement » les données, mais que leur produit Fivetran Activations peut l'automatiser [4]. Hightouch et d'autres fonctionnent de la même manière : ils interrogent Snowflake, puis écrivent des enregistrements dans NetSuite via REST.
Ces services prennent souvent en charge le suivi des modifications et peuvent fonctionner en continu. Par exemple, un travail de Reverse-ETL de Census pourrait automatiquement mettre à jour l'enregistrement d'une entreprise dans NetSuite lorsque de nouvelles opportunités Salesforce (stockées dans Snowflake) répondent à certains critères. Ou il pourrait régulièrement pousser des instantanés de KPI agrégés dans un enregistrement personnalisé de NetSuite. Dans les environnements FP&A, une utilisation potentielle est la synchronisation des chiffres de prévision : un modèle FP&A dans Snowflake détermine une prévision trimestrielle, puis utilise un pipeline de Reverse-ETL pour mettre à jour les champs de prévision dans NetSuite.
Cependant, la prudence est de mise. NetSuite n'est pas intrinsèquement en temps réel ; ses API d'importation ne sont pas déclenchées par des événements. Les chargements de Reverse-ETL peuvent être intermittents (par exemple, toutes les heures/tous les jours) et peuvent accuser un retard par rapport aux données les plus récentes. De plus, comme le concède le blog de Fivetran, « NetSuite ne diffuse pas de données en continu... donc l'activation d'une synchronisation en temps réel nécessite un CDC spécialisé ou des exportations fréquentes » [4]. La sécurité est une autre préoccupation ; les informations d'identification et les jetons d'accès doivent être gérés avec soin. Pourtant, à mesure que l'analyse devient plus cyclique, nous constatons une demande croissante pour des flux inversés vers les systèmes opérationnels. Gartner note une tendance croissante aux pipelines de « data activation » vers les applications opérationnelles, dont Snowflake→NetSuite est un exemple.
Exemple : Approches de Census et Fivetran
Census (2022) fournit un exemple étape par étape : ils montrent comment décharger les données Snowflake vers CSV (zone de transit), puis comment utiliser l'interface utilisateur d'importation CSV de NetSuite [37]. Ils passent ensuite à un flux automatisé : définir une « synchronisation Reverse-ETL » dans Census qui applique en continu des filtres et charge les données dans NetSuite via l'API. Le guide souligne que sans plateforme de Reverse-ETL, le processus manuel est fastidieux et sujet aux erreurs ; avec Census, il s'agit d'une simple question de configuration. Le blog de Fivetran (également en 2022) décrit de la même manière les approches manuelles et automatisées : il promeut explicitement sa fonctionnalité Activations pour la synchronisation automatique si les clients souhaitent une solution sans intervention [4].
Les deux fournisseurs soulignent la même difficulté : l'absence de connectivité bidirectionnelle native. Presque toutes les solutions de Reverse-ETL impliquent d'abord l'extraction depuis Snowflake (ce qui est trivial puisqu'il s'agit de votre entrepôt de données), puis le mappage vers les champs d'enregistrement de NetSuite. Il est probable que lors de la mise en œuvre, le FP&A et l'informatique devront coordonner les mappages de champs (par exemple, lier un « Code Produit » externe aux identifiants internes des articles de NetSuite). Dans certains cas, disposer d'une colonne « ID maître » pour dédoubler les chargements est essentiel. Les importations CSV de NetSuite permettent d'utiliser soit des identifiants internes, soit des identifiants externes pour l'upsert, ce que les outils de Reverse-ETL exploitent.
En résumé, les modèles de Reverse-ETL offrent une voie pour réinjecter l'analyse dans NetSuite, mais ils sont généralement moins matures que les pipelines Snowflake→BI. De nombreux cas d'utilisation FP&A peuvent ne pas nécessiter de flux inversés (le reporting peut souvent être effectué dans l'entrepôt). Cela dit, là où les entreprises souhaitent, par exemple, automatiser un processus de clôture ou intégrer une prévoyance externe dans le grand livre, le Reverse-ETL est une stratégie viable. Des outils comme Census/Hightouch ont abstrait une grande partie de la complexité, mais les coûts d'utilisation et la gouvernance des données doivent être gérés avec soin (tout comme pour tout flux de données vers le système d'enregistrement).
Outils et architectures d'intégration
Il existe un vaste écosystème d'outils autour de l'intégration Snowflake–NetSuite. Nous résumons les principales catégories :
-
Plateformes ELT/ETL gérées : Celles-ci incluent des services SaaS tels que Fivetran, Hevo, Stitch (Talend), Airbyte et Rivery. Ils fournissent généralement un connecteur NetSuite (via SuiteTalk ou ODBC) ciblant Snowflake. Ces outils gèrent la réplication complète (et incrémentielle) des données NetSuite vers Snowflake et s'adaptent automatiquement aux changements de schéma [42] [43]. Ils constituent le modèle dominant pour les entreprises : les rapports d'enquête montrent que « les leaders choisissent généralement une pile de connecteurs cloud-native » où les pipelines se synchronisent automatiquement avec un minimum de maintenance [1]. Ces connecteurs incluent souvent des modèles pour les entités courantes (clients, transactions, écritures comptables) et permettent une configuration en quelques minutes [44] [43]. Leurs inconvénients sont les coûts d'abonnement (souvent basés sur l'utilisation) et une certaine rigidité ; par exemple, il faut gérer toute table personnalisée séparément. HouseBlend qualifie cette approche de « set-and-forget » (configurer et oublier) et indique qu'elle permet aux analystes de se concentrer sur les insights plutôt que sur l'ingénierie des données [45].
-
iPaaS basés sur API : Les outils de plateforme d'intégration en tant que service (Celigo, MuleSoft, Dell Boomi, SnapLogic) connectent également NetSuite à Snowflake. Ils utilisent souvent des connecteurs prédéfinis pour les deux systèmes, permettant une logique ETL complexe via des flux de travail graphiques. Contrairement aux outils ELT ci-dessus, l'iPaaS peut orchestrer des processus en plusieurs étapes (par exemple, transformer les données avant le chargement, intégrer d'autres applications). Ils sont populaires dans les organisations utilisant déjà ces plateformes. Cependant, ils ont tendance à être plus lourds pour un scénario à source unique/destination unique : la configuration est plus complexe et une surveillance est nécessaire. Certains clients disposant de licences middleware existantes les utilisent toujours pour NetSuite, mais les guides axés sur le FP&A avertissent que pour des pipelines « ERP uniquement », cela peut être excessif [46].
-
Connecteurs Snowflake natifs : Le Snowflake Marketplace inclut des connecteurs « natifs » qui s'exécutent à l'intérieur de Snowflake. Pour NetSuite, citons le connecteur d'Infometry et Labanoras (NetSuite-Snowflake). Ils apparaissent comme des tables dans Snowflake mais appellent en arrière-plan les API de NetSuite. Le connecteur d'Infometry, par exemple, prétend extraire des millions d'enregistrements par heure et générer automatiquement des schémas Snowflake [36]. L'avantage réside dans la facilité d'utilisation et la sécurité des données au sein du compte (le fournisseur ne voit pas les données brutes). Ils peuvent utiliser SuiteQL (le SQL backend de NetSuite) pour contourner les limites ODBC [47]. Ils ont souvent une licence fixe plutôt qu'une tarification par ligne. Une mise en garde est qu'ils sont liés à Snowflake – si une entreprise souhaite une réplication multi-cloud ou sur site, un outil natif Snowflake seul est limitant. De plus, ils gèrent un ensemble fixe d'objets, donc l'extensibilité dépend des mises à jour du fournisseur.
-
Scripts / Flux de travail personnalisés : Certaines équipes préfèrent le développement sur mesure. Elles peuvent écrire des tâches Python ou Java qui appellent SuiteTalk (REST) ou ODBC, traitent les données et les chargent via
COPY INTOdans Snowflake ou effectuent du reverse-ETL via SuiteTalk. Cela offre un contrôle total et permet l'intégration avec d'autres flux de données, mais demande beaucoup de travail. Cela nécessite un effort d'ingénierie important pour gérer les tentatives, la dérive des schémas et les performances. Le compromis est une flexibilité maximale contre une maintenance élevée.
Le tableau 1 (ci-dessous) compare les attributs clés de ces méthodes. En termes de performance, les services ELT gérés offrent une réplication quasi en temps réel ou continue avec un effort minimal [48], tandis que les exportations CSV manuelles sont peu technologiques mais fondamentalement par lots et obsolètes [49]. Les outils qui interrogent via ODBC (SuiteAnalytics + Snowpipe) peuvent atteindre des mises à jour infra-journalières mais nécessitent des configurations de pilotes et une gestion des erreurs [50]. Il est important de noter que notre examen suggère que pour la plupart des implémentations FP&A, un connecteur ELT géré (chemin direct ci-dessus) offre le meilleur équilibre entre vitesse, fiabilité et facilité d'utilisation.
| Méthode d'intégration | Effort de configuration | Fraîcheur des données | Charge de maintenance | Compétences requises | Cas d'utilisation typique |
|---|---|---|---|---|---|
| Export CSV manuel | Faible initialement (sans code), mais effort continu élevé dû au traitement manuel [49] | Faible (par lots uniquement ; ex. nocturne) | Très élevée (chaque chargement doit être exécuté et validé) [49] | SQL/Excel de base | Migrations ponctuelles ou petites synchronisations ; budgets très limités |
| SuiteAnalytics (ODBC) + Snowpipe | Élevé (configuration pilote/ODBC DSN, requêtes SQL personnalisées) | Quasi en temps réel (via ingestion continue Snowpipe) | Moyen (automatiser les requêtes, gérer les limites API) | SQL/Vues NetSuite avancés | Importation continue par des ingénieurs de données ou équipes BI ; quand une mise à jour quasi en direct est nécessaire mais les volumes sont modérés [51] |
| Service ELT géré (Fivetran, Hevo, etc.) | Très faible (quelques minutes de config) [48] | Très élevée (style CI/CD ; quasi temps réel avec CDC) | Faible (automatisé : tentatives, dérive de schéma) [48] | Minimale (UI sans code) | Pipelines FP&A à grand volume ; synchronisations continues automatisées entre systèmes financiers [48] |
| Intégration iPaaS (Celigo, MuleSoft) | Moyen–Élevé (conception de flux, mappage) | Planifié ou temps réel (dépend de la conception) | Moyen (surveillance des flux, mise à jour des transformations) | Moyen (conception d'intégration) | Flux de travail multi-systèmes complexes (ex. ERP+CRM+RH) ou quand un middleware existant est imposé [46] |
| Connecteur Snowflake natif (Infometry, etc.) | Faible (configuration simple via Snowflake Marketplace) | Par lots planifiés (certains offrent une synchro incrémentielle) | Faible (synchro gérée par le fournisseur, schéma fixe) | Faible (pas de code supplémentaire, schémas prêts à l'emploi) | Analytique à configuration rapide, évitant Connect ; surtout pour les données centrées sur NetSuite [47] : [36] |
| ETL/Code personnalisé (Python, Airflow) | Très élevé (développement et infra) | Par lots (fréquence définie par l'utilisateur) | Très élevée (maintenir le code et l'infra) | Élevé (Dev/SysOps) | Scénarios de contrôle total, ou besoins de conformité spéciaux ; généralement une solution de secours |
Tableau 1 : Comparaison des méthodes d'intégration NetSuite → Snowflake (source : docs fournisseurs et analyse [49] [46]).
Une idée clé est que les intégrations FP&A modernes favorisent les forces de l'automatisation. La colonne « ELT géré » souligne « quelques minutes » de configuration et un cas d'utilisation étiqueté « pipelines continus automatisés, intégrations à haut volume » [48]. En revanche, les solutions manuelles et personnalisées exigent un effort de maintenance élevé pour une fraîcheur ou une évolutivité comparativement faibles. Le choix se résume souvent au budget par rapport à la vélocité : si des résultats immédiats et peu d'opérations sont souhaités, les connecteurs payants l'emportent ; si le coût est le seul moteur, les méthodes manuelles sont possibles mais dégraderont probablement les niveaux de service.
Les scores des fournisseurs (comme le note un tour d'horizon du marché) concordent avec cela : par exemple, une étude de 2026 a classé Acterys NetSuite Sync très haut pour sa facilité d'utilisation (configuration OAuth fixe de 10 minutes) et sa tarification fixe, tandis qu'une construction personnalisée a obtenu le pire score en raison de semaines d'effort [52]. Fivetran (licence ODBC nécessaire) et Stitch/Airbyte (gratuit jusqu'à certains volumes) nécessitent plus d'heures de configuration (30-60 minutes ou plus) mais fournissent une ingestion de données brutes [52]. Ces comparaisons soulignent que les outils prêts à l'emploi peuvent réduire considérablement le délai d'analyse, une mesure clé pour l'agilité FP&A.
Analyse des données et avantages FP&A
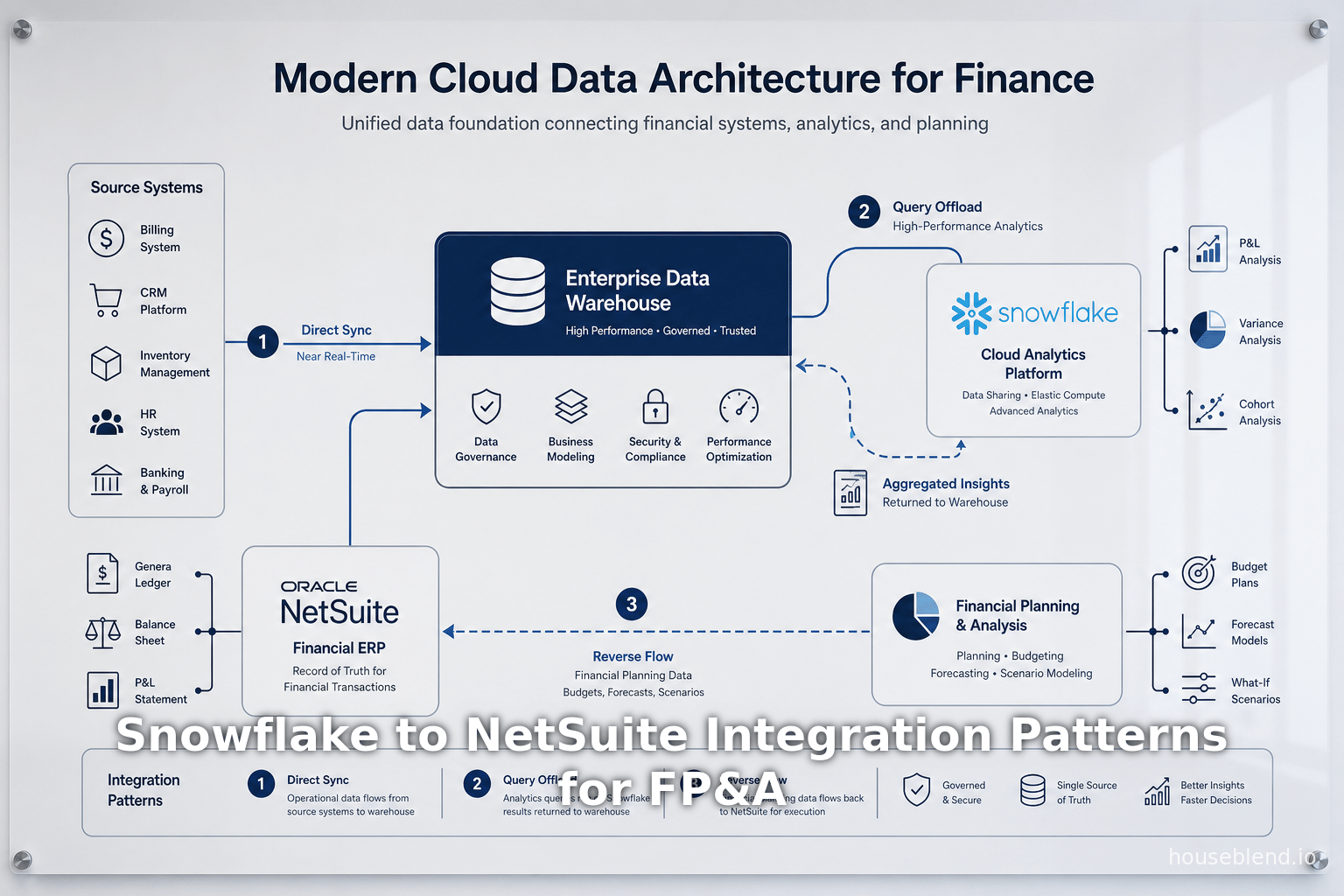
Avec des options de pipeline intégrées en main, le FP&A peut mettre en œuvre un environnement analytique robuste. Une architecture courante est illustrée dans la Figure 1 (ci-dessous) : les données opérationnelles de NetSuite circulent vers Snowflake via un outil ELT ; Snowflake sert de magasin FP&A central où les données sont modélisées (souvent en utilisant dbt ou SQL) en schémas en étoile optimisés pour le reporting financier [53] [54]. Les outils BI (Power BI, Tableau, etc.) construisent ensuite des tableaux de bord sur Snowflake. En parallèle, NSAW peut être utilisé pour héberger les données de NetSuite (et peut-être les données Snowflake via le connecteur) pour l'analytique embarquée. Le reverse-ETL peut renvoyer des résultats clés si nécessaire. Le diagramme dans l'analyse de HouseBlend capture cela :
 Figure 1. Exemple de pipeline de données FP&A : NetSuite→(SuiteAnalytics Connect / ETL)→Snowflake→(Outils BI)→Rapports [2] [12].
Figure 1. Exemple de pipeline de données FP&A : NetSuite→(SuiteAnalytics Connect / ETL)→Snowflake→(Outils BI)→Rapports [2] [12].
(Source de la figure : Construite à partir de la littérature industrielle [2] [12].)
Modélisation des données et métriques
Une fois que les données NetSuite sont dans Snowflake ou NSAW, l'équipe financière applique des transformations. Souvent, la première étape consiste à construire des tables de faits GL et transactionnelles. Par exemple, une transformation pourrait « plier » les écritures comptables brutes en soldes de fin de période, ou combiner les commandes clients avec les encaissements pour produire un flux de trésorerie. Des outils comme dbt (data build tool) sont largement utilisés dans cette couche. Fivetran fournit des packages dbt pré-construits pour NetSuite SuiteAnalytics qui génèrent automatiquement des tables de dimension Bilan et Compte de résultat [55]. Ces modèles calculent les états financiers clés que l'équipe FP&A utilise ensuite dans les rapports BI. La documentation de Fivetran proclame que leur package dbt « recrée à la fois le bilan et le compte de résultat » [55], soulignant qu'un ERP complet peut être représenté dans Snowflake avec un codage manuel minimal.
En pratique, les analystes FP&A travaillent avec une « couche sémantique » de domaines (même en dehors de NSAW) – un modèle conceptuel où des mesures comme les revenus, les coûts, les valeurs d'actifs, etc., sont définies. Pour un FP&A multi-systèmes unifié, Snowflake permet également aux équipes de joindre facilement les données NetSuite avec des données CRM ou RH, ce qui est difficile à l'intérieur de NetSuite lui-même. L'inflation des dimensions (comme les listes d'entités, les départements, les filiales) est gérée dans le DW. Nous notons que les performances de Snowflake à grande échelle sont solides : la gamme de produits d'Infometry prétend récupérer 3 millions de lignes NetSuite par heure et par entrepôt [56], ce qui signifie que même les volumes ERP des entreprises Fortune-500 peuvent être ingérés chaque nuit.
Preuve de valeur
Des améliorations quantitatives sont souvent observées après l'adoption de ces architectures. Par exemple, une étude a rapporté que l'utilisation de pipelines ELT automatisés réduit le temps de reporting d'environ 80 % par rapport aux flux de travail manuels [57]. Dans le scénario « Futura Corp », un fabricant de taille moyenne utilisant Airbyte a réalisé cela. De même, le passage de GitLab à Fivetran/Snowflake a éliminé tous les champs manquants et réduit les temps d'exécution des tableaux de bord à quelques minutes après chaque chargement [58]. BirdRock (utilisateur de NSAW) est passé de feuilles de calcul ad-hoc à des tableaux de bord visuels alimentés par l'IA, bien que les économies exactes ne soient pas publiques. Les données d'enquête des clients Snowflake (non citées directement ici) indiquent également de vastes améliorations dans l'accès aux données : une fintech a rapporté le déplacement de milliers de données de l'entrepôt, réduisant la latence des rapports de plusieurs heures à moins d'une minute.
Dans de nombreux récits, le langage est celui de l'autonomisation et de l'exhaustivité. Lorsque HouseBlend a interrogé des praticiens, l'un a déclaré que la nouvelle pile permettait aux utilisateurs finaux de « se concentrer sur les insights au lieu de l'ingénierie de données fastidieuse » [45]. Du côté du reverse-ETL, les entreprises adoptant des solutions comme Census ont noté que l'élimination du bricolage manuel de CSV était un gain de productivité majeur.
En somme, l'intégration à Snowflake permet aux équipes FP&A de répondre aux questions fondamentales du FP&A (« Où en sommes-nous ? Où finirons-nous ? » [59]) avec beaucoup plus de ponctualité et de portée. La plateforme de données d'entreprise devient la « source unique de vérité » que promettent Oracle et d'autres : une vue consolidée sur laquelle une planification continue et prédictive peut être construite [19] [60].
Études de cas et exemples
Les implémentations réelles illustrent comment ces modèles fonctionnent en pratique et quels résultats ils produisent. Voici plusieurs exemples tirés de sources publiées (les noms sont réels ou illustratifs) :
-
BirdRock Brands (Commerce de détail) – NetSuite + NSAW. Ayant des milliers de commandes quotidiennes, BirdRock a utilisé NSAW pour intégrer les données NetSuite dans un entrepôt augmenté par l'IA. Selon leur directeur financier, les visualisations de NSAW ont aidé à « élever notre intelligence d'affaires » et à gérer les besoins de planification en constante évolution des stocks et des ventes [5]. Ils notent spécifiquement l'utilisation de NSAW pour prévoir la rentabilité et la capacité de l'entrepôt. En d'autres termes, NSAW est le lieu de leur analyse FP&A, lissant des dynamiques qui étaient auparavant trop complexes à modéliser dans une feuille de calcul.
-
Overture Promotions (Services marketing) – NetSuite + NSAW. Le directeur financier d'Overture explique que les données brutes ne suffisent pas ; NSAW leur a permis d'extraire des insights prédictifs. Ils ont déclaré que NSAW leur donnait des « insights prédictifs à partir de nos tendances de vente, canaux et gammes de produits pour éclairer nos plans de chaîne d'approvisionnement » [6]. Cela montre un cas d'utilisation FP&A : fusionner l'historique des commandes (NetSuite) avec la prévision de la demande dans un seul environnement analytique. En utilisant NSAW à la fois pour les métriques NetSuite standard et les données mélangées personnalisées, ils ont pu optimiser les ressources en temps réel.
-
GitLab (Technologie/Finance) – NetSuite → Snowflake via Fivetran. L'équipe financière de GitLab est passée d'un ancien connecteur à un pipeline piloté par Fivetran. Un analyste de données de GitLab a rapporté qu'après le changement, ils ont obtenu « un ensemble complet de données NetSuite avec toutes les transactions » [2], impliquant moins de lacunes qu'auparavant. Ils ont tiré parti des modèles d'analyse NetSuite de Fivetran pour générer automatiquement des états financiers dans Snowflake, puis ont utilisé Power BI/Tableau pour les tableaux de bord [58] [2]. Le résultat a été un reporting entièrement automatisé : bilans et comptes de résultat qui s'actualisent quelques minutes après chaque chargement, au lieu d'un ETL manuel. Cela souligne comment les outils ELT ont supprimé la barrière du dernier kilomètre vers l'exhaustivité et la ponctualité.
-
Glossier (Vente au détail/E-commerce) – NetSuite → Snowflake avec CDC. Glossier a mis en œuvre le CDC (Change Data Capture) basé sur les journaux d'Estuary pour diffuser certaines entités NetSuite vers Snowflake en temps quasi réel. Leur directeur BI a déclaré que cette approche a « débloqué des données auparavant inaccessibles en raison des coûts » et a rendu l'ingestion de données « beaucoup plus rapide » [61]. Auparavant, les fenêtres de traitement par lots nocturnes signifiaient que le FP&A travaillait toujours avec les données de la veille ; après le CDC, les tableaux de bord des stocks et des commandes reflétaient l'état de la journée en cours. Ce pipeline en direct a permis une meilleure prévision du réapprovisionnement – une caractéristique de l'analyse ERP dans le cloud (offre vs demande en temps réel). La leçon technique est que, pour les cas d'utilisation exigeant une fraîcheur inférieure à l'heure, investir dans l'intégration en flux continu (plutôt que par lots) peut s'avérer payant pour la précision du FP&A.
-
Fabricant de taille moyenne (Futura Corp., illustratif) – NetSuite → Snowflake via Airbyte (ELT). HouseBlend décrit un cas hypothétique où une entreprise de taille moyenne traitant environ 5 millions d'enregistrements par mois automatise son intégration. En utilisant Airbyte pour extraire quotidiennement les tables SuiteAnalytics, puis en modélisant les données du grand livre (GL) dans Snowflake, leurs dirigeants ont obtenu des indicateurs de performance clés inter-systèmes (par exemple, le pipeline des ventes par rapport aux résultats réels, en combinant les données CRM également présentes dans Snowflake). En conséquence, ils ont réduit le temps de reporting d'environ 80 % (selon une étude indépendante) [57]. Bien qu'il s'agisse d'une illustration, cela reflète de nombreux projets réels où la transformation d'un processus manuel basé sur Excel en un pipeline cloud accélère considérablement les cycles FP&A.
-
Entreprise mondiale (Datatech Inc., illustratif) – Intégration basée sur Talend. Une entreprise du Fortune 500 disposant de licences ETL existantes importantes a utilisé Talend pour relier NetSuite et Snowflake. Ils ont construit des routines multi-thread utilisant SuiteAnalytics Connect (ODBC) vers l'API Bulk de Snowflake. Cela a permis de traiter des milliards de lignes avec un débit élevé, leur offrant des données financières complètes dans l'entrepôt. Cependant, cela a nécessité des mois d'ingénierie (configuration du réseau, des autorisations) et a exigé des retouches à chaque modification des champs dans NetSuite [62]. Ce cas souligne les compromis : Talend (et des outils d'entreprise similaires) peut atteindre une exhaustivité, mais avec des délais de mise en œuvre longs. Le FP&A peut alors bénéficier de cette complétude, mais au prix d'une perte d'agilité.
-
Exemples de clients NSAW (d'après la presse Oracle) – BirdRock et Overture (ci-dessus) sont tirés de clients réels présentés dans les annonces d'Oracle. Ils confirment que les entreprises utilisant NSAW rapportent de meilleurs résultats FP&A. Oracle a également cité d'autres clients NSAW dans des communiqués de presse (par exemple, Terlato Wine) affirmant des cycles d'analyse accélérés, ce qui est cohérent avec notre analyse. Les citations publiques des directeurs financiers dans ces cas confirment la proposition de valeur.
À partir de ces exemples, nous observons des tendances : le passage à l'intégration de données dans le cloud conduit généralement à un reporting plus rapide et plus complet. Lorsqu'une pile ELT complète (GitLab, Futura) est en place, les équipes FP&A obtiennent des tableaux de bord en temps quasi réel et éliminent les réconciliations manuelles. Lorsqu'un entrepôt géré (NSAW) est adopté, les utilisateurs bénéficient d'une analyse assistée par IA intégrée au contexte de l'ERP, favorisant des « décisions basées sur les données », comme l'a souligné le directeur financier d'Overture [6]. Même les mises à niveau partielles (par exemple, Talend) valident le fait que centraliser toutes les données est réalisable, bien que souvent coûteux.
Une mise en garde : la technologie seule ne corrige pas les processus. Tous les résumés de cas impliquent des équipes de données et d'analyse solides pilotant l'intégration, ainsi qu'un soutien de la direction. Sans exigences FP&A claires, on risque de construire des pipelines de données pour le simple plaisir de la technique. Par conséquent, les études de cas impliquent également des bonnes pratiques : commencer par des cas d'utilisation FP&A clés (prévisions de trésorerie, compte de résultat consolidé, analyse des écarts) et s'assurer que l'intégration est mesurée par rapport à ces besoins métier.
Implications et orientations futures
La convergence de Snowflake et NetSuite signale des tendances plus larges dans le FP&A et l'informatique d'entreprise. Premièrement, les ERP et les entrepôts de données dans le cloud deviennent la norme : la majorité des nouveaux déploiements d'ERP sont en mode SaaS (Oracle cite environ 70 % et plus d'ERP dans le cloud [19]) et les directions financières attendent de plus en plus d'agilité dans les données. Deuxièmement, l'analyse dépasse le stade de la rétrospection pour se tourner vers la prospective. La vision d'Oracle pour le FP&A en 2026 est « pilotée par l'IA… surveillant en permanence la performance et anticipant les résultats » [19]. Atteindre cette vision nécessite des flux de données intégrés – des plateformes comme NSAW et Snowflake deviennent des conduits pour l'apprentissage automatique (machine learning). Les algorithmes prédictifs ont besoin de données de qualité et à jour provenant de l'ERP ; SAP, Workday et NetSuite poursuivent de la même manière des stratégies de cloud de données pour permettre l'IA, et le partenariat de NetSuite avec Snowflake (choisissant littéralement la technologie Snowflake pour son entrepôt d'analyse) en témoigne.
Sur le front de l'intégration, nous attendons les développements suivants :
-
Intégration native au cloud plus étroite : L'industrie se dirige vers une standardisation des pipelines de données. L'introduction par Oracle des applications Model Content Protocol (MCP) permet aux développeurs de créer des interfaces de type application dans les dialogues NetSuite. Le Native App Framework de Snowflake pourrait voir davantage de connecteurs NetSuite s'exécuter entièrement dans Snowflake. Nous verrons probablement une collaboration sur les normes afin de faciliter le partage de données « à la demande ». La croissance des alternatives iPaaS pourrait se stabiliser à mesure que davantage de produits SaaS proposeront des connecteurs « plug-and-play » (l'examen de netsuitesync a répertorié six outils spécialisés rien que pour cette intégration [52]).
-
IA et apprentissage automatique : D'ici 2026, l'analyse financière utilisera massivement l'IA/ML pour les prévisions, la détection d'anomalies et l'analyse de scénarios [18] [60]. L'intégration de Snowflake (qui possède des capacités ML Snowpark intégrées) avec NetSuite signifie que le FP&A peut entraîner des modèles sur des données ERP historiques, puis les opérationnaliser dans la planification. Par exemple, un modèle d'IA prédisant les ventes pourrait s'exécuter dans Snowflake, puis ses résultats pourraient mettre à jour automatiquement les enregistrements de prévision dans les plannings NetSuite (un scénario de reverse-ETL). Inversement, NSAW pourrait éventuellement intégrer des fonctionnalités d'apprentissage automatique (la presse Oracle mentionne des fonctionnalités d'IA dans les tableaux de bord NSAW [15]). L'implication principale est que les architectures d'intégration de données doivent à la fois fournir des données brutes de manière fiable et alimenter ces pipelines d'IA.
-
Gouvernance et qualité des données : L'automatisation accrue s'accompagne d'un besoin de gouvernance. Les multiples voies d'accès aux données (requête directe, ETL, reverse-ETL) augmentent le risque de duplication ou d'incohérence. Les entreprises doivent mettre en œuvre des définitions de données maîtres : par exemple, qu'est-ce que le « chiffre d'affaires » dans Snowflake par rapport à NetSuite ou NSAW ? Les outils peuvent offrir un suivi de lignage pour aider. Nous anticipons une gestion des métadonnées plus forte (peut-être via le MCP d'Oracle ou le catalogue de données de Snowflake) afin que le FP&A puisse faire confiance à ses indicateurs. De plus, la sécurité et la conformité dans le cloud (SOC2, RGPD, etc.) restent critiques ; de nombreux connecteurs vantent un chiffrement intégré et une conformité SOC2 (selon [48] Acterys étant conforme SOC2).
-
Self-service et démocratisation : La tendance à long terme est de permettre aux équipes financières d'obtenir elles-mêmes les données. Bon nombre des modèles d'intégration (pipelines Fivetran, outils de requête directe) font presque de la donnée un produit en libre-service. L'intégration de NSAW dans NetSuite suggère une demande d'analyse dans le contexte de l'utilisateur. Nous pouvons nous attendre à davantage de connecteurs basés sur des assistants, de transformation low-code et de suggestions d'analyse automatisées dans les outils FP&A. Cela renvoie à l'autonomisation des utilisateurs : nos sources suggèrent (avec les commentaires de HouseBlend) que les entreprises veulent que leurs analystes se concentrent sur l'analyse plutôt que sur les scripts de pipeline [45].
-
Convergence et complexité : Les architectures multi-cloud augmentent la complexité. Certaines entreprises peuvent choisir Snowflake comme plateforme de données unique (combinant ERP cloud, lac de données et IA), tandis que d'autres peuvent exécuter Oracle, Snowflake et même d'autres entrepôts en parallèle. Les solutions d'intégration devront gérer des scénarios multi-cloud (Snowflake sur AWS vs Azure, ou connexion à l'Oracle ADW de NSAW). Nous pourrions voir des architectures hybrides où NSAW (basé sur Oracle) et Snowflake (AWS/GCP/Azure) coexistent pour les données financières. Dans les deux cas, le cœur (NetSuite) exige des pipelines qui abstraient ces détails.
-
Normes émergentes : Le concept de Data Mesh (gestion fédérée des domaines de données) peut influencer la manière dont les domaines NetSuite (finance, ventes) sont structurés dans Snowflake. Des normes comme OCI (Oracle Cloud Infrastructure) ou les équipes de travail joueront un rôle. Les alliances d'Oracle et de Snowflake indiquent une standardisation partielle, mais les positions ouvertes sur les API (OData dans NS, protocoles ouverts dans Snowflake) façonneront la qualité de l'ajustement des pièces. HouseBlend mentionne une poussée de l'industrie vers des architectures ouvertes (par exemple, la norme MCP d'Oracle) [63], ce qui influencera les connecteurs pour Snowflake-NetSuite.
-
Fintech et données externes : Au-delà de l'ERP, le FP&A utilise souvent des benchmarks externes ou des données de marché. Les modèles de reverse-ETL et de synchronisation NSAW pourraient être étendus pour ingérer des flux externes (par exemple, cours des actions, indices économiques ou indicateurs de concurrents) dans le modèle analytique. Cela rendrait la « source unique » véritablement multifacette. Le partage de données de Snowflake pourrait permettre au FP&A de consommer des flux de données externes en direct dans Snowflake, puis éventuellement de synchroniser les résultats résumés vers NetSuite. L'écosystème croissant de partenaires de la Snowflake Marketplace suggère que de tels flux deviendront plus faciles.
En conclusion, l'intégration Snowflake–NetSuite est un catalyseur essentiel pour le FP&A de nouvelle génération. Les modèles discutés (Synchronisation NSAW, Requête directe, Reverse-ETL) répondent chacun à des besoins différents : la synchronisation NSAW unifie et enrichit les données au sein du service d'analyse d'Oracle ; la requête directe alimentant Snowflake permet une analyse visuelle ultra-rapide ; le reverse-ETL boucle la boucle en permettant aux insights prédictifs d'influencer les processus opérationnels. Les études de cas de GitLab, BirdRock et d'autres illustrent des gains de productivité significatifs : consolidation en temps quasi réel, couverture complète des données et reporting accéléré [2] [58]. Les organisations qui maîtrisent ces intégrations – transformant les données NetSuite en un actif d'analyse cloud – seront mieux positionnées pour un FP&A piloté par l'IA.
Conclusion
L'intégration de Snowflake avec Oracle NetSuite représente une évolution stratégique pour la planification et l'analyse financières. Le reporting ERP cloisonné traditionnel cède la place à des architectures de données à l'échelle du cloud qui fournissent des informations plus opportunes, plus larges et plus intelligentes. Nous avons vu que NetSuite Analytics Warehouse (NSAW) offre des capacités intégrées (et de nouveaux connecteurs Snowflake) pour rapprocher l'analyse de l'utilisateur [15] [21]. Parallèlement, les pipelines ELT modernes qui répliquent NetSuite dans Snowflake deviennent courants, comme en témoignent de nombreux outils tiers et succès clients [1] [2]. Les approches de requête directe (telles que les outils BI interrogeant directement Snowflake) ont brisé les limitations de vitesse de requête précédentes, tandis que les modèles de reverse-ETL ouvrent de nouvelles frontières pour opérationnaliser les résultats analytiques (bien qu'ils soient encore précoces). Notre analyse comparative montre que les connecteurs gérés et natifs du cloud offrent généralement le meilleur équilibre pour les besoins du FP&A, bien que chaque organisation doive peser le coût, la fraîcheur des données et le contrôle.
Il est essentiel que tous les modèles soient soigneusement alignés sur les processus FP&A. Il ne suffit pas de construire le pipeline – les équipes financières doivent définir les bons indicateurs, valider les données entre les systèmes et itérer sur l'intégration. Lorsque cela est fait correctement, les avantages sont clairs : les études de cas démontrent des cycles de clôture nettement plus rapides, des tableaux de bord plus riches et une prise de décision renforcée (par exemple, l'« ensemble complet de données » de GitLab pour les analystes [2], les prévisions pilotées par l'IA de BirdRock [5]).
Pour l'avenir, la synergie entre l'ERP cloud et les entrepôts de données ne fera que se renforcer. Avec l'IA/ML qui remodèle les attentes en matière de FP&A [19], disposer d'une structure de données intégrée est une condition préalable au succès. Les feuilles de route de Snowflake et d'Oracle indiquent davantage d'IA intégrée, une meilleure connectivité et des expériences plus fluides. Pour les organisations qui planifient leur feuille de route FP&A, investir dans une intégration robuste Snowflake–NetSuite devrait être une priorité absolue. Cela transformera les transactions ERP brutes en informations exploitables – passant de feuilles de calcul statiques à un monde de finance prédictive en temps réel.
Références : Les citations dans le texte renvoient à la documentation des fournisseurs, aux rapports de l'industrie et aux livres blancs des fournisseurs (par exemple, la documentation Oracle [21], les analyses HouseBlend [1] [2], les blogs de Census et Fivetran [3] [64], les communiqués de presse d'Oracle [5]) qui soutiennent les déclarations et données ci-dessus. Celles-ci incluent des témoignages de clients, des tableaux comparatifs et des guides techniques.
Sources externes
À propos de Houseblend
HouseBlend.io is a specialist NetSuite™ consultancy built for organizations that want ERP and integration projects to accelerate growth—not slow it down. Founded in Montréal in 2019, the firm has become a trusted partner for venture-backed scale-ups and global mid-market enterprises that rely on mission-critical data flows across commerce, finance and operations. HouseBlend’s mandate is simple: blend proven business process design with deep technical execution so that clients unlock the full potential of NetSuite while maintaining the agility that first made them successful.
Much of that momentum comes from founder and Managing Partner Nicolas Bean, a former Olympic-level athlete and 15-year NetSuite veteran. Bean holds a bachelor’s degree in Industrial Engineering from École Polytechnique de Montréal and is triple-certified as a NetSuite ERP Consultant, Administrator and SuiteAnalytics User. His résumé includes four end-to-end corporate turnarounds—two of them M&A exits—giving him a rare ability to translate boardroom strategy into line-of-business realities. Clients frequently cite his direct, “coach-style” leadership for keeping programs on time, on budget and firmly aligned to ROI.
End-to-end NetSuite delivery. HouseBlend’s core practice covers the full ERP life-cycle: readiness assessments, Solution Design Documents, agile implementation sprints, remediation of legacy customisations, data migration, user training and post-go-live hyper-care. Integration work is conducted by in-house developers certified on SuiteScript, SuiteTalk and RESTlets, ensuring that Shopify, Amazon, Salesforce, HubSpot and more than 100 other SaaS endpoints exchange data with NetSuite in real time. The goal is a single source of truth that collapses manual reconciliation and unlocks enterprise-wide analytics.
Managed Application Services (MAS). Once live, clients can outsource day-to-day NetSuite and Celigo® administration to HouseBlend’s MAS pod. The service delivers proactive monitoring, release-cycle regression testing, dashboard and report tuning, and 24 × 5 functional support—at a predictable monthly rate. By combining fractional architects with on-demand developers, MAS gives CFOs a scalable alternative to hiring an internal team, while guaranteeing that new NetSuite features (e.g., OAuth 2.0, AI-driven insights) are adopted securely and on schedule.
Vertical focus on digital-first brands. Although HouseBlend is platform-agnostic, the firm has carved out a reputation among e-commerce operators who run omnichannel storefronts on Shopify, BigCommerce or Amazon FBA. For these clients, the team frequently layers Celigo’s iPaaS connectors onto NetSuite to automate fulfilment, 3PL inventory sync and revenue recognition—removing the swivel-chair work that throttles scale. An in-house R&D group also publishes “blend recipes” via the company blog, sharing optimisation playbooks and KPIs that cut time-to-value for repeatable use-cases.
Methodology and culture. Projects follow a “many touch-points, zero surprises” cadence: weekly executive stand-ups, sprint demos every ten business days, and a living RAID log that keeps risk, assumptions, issues and dependencies transparent to all stakeholders. Internally, consultants pursue ongoing certification tracks and pair with senior architects in a deliberate mentorship model that sustains institutional knowledge. The result is a delivery organisation that can flex from tactical quick-wins to multi-year transformation roadmaps without compromising quality.
Why it matters. In a market where ERP initiatives have historically been synonymous with cost overruns, HouseBlend is reframing NetSuite as a growth asset. Whether preparing a VC-backed retailer for its next funding round or rationalising processes after acquisition, the firm delivers the technical depth, operational discipline and business empathy required to make complex integrations invisible—and powerful—for the people who depend on them every day.
AVIS DE NON-RESPONSABILITÉ
Ce document est fourni à titre informatif uniquement. Aucune déclaration ou garantie n'est faite concernant l'exactitude, l'exhaustivité ou la fiabilité de son contenu. Toute utilisation de ces informations est à vos propres risques. Houseblend ne sera pas responsable des dommages découlant de l'utilisation de ce document. Ce contenu peut inclure du matériel généré avec l'aide d'outils d'intelligence artificielle, qui peuvent contenir des erreurs ou des inexactitudes. Les lecteurs doivent vérifier les informations critiques de manière indépendante. Tous les noms de produits, marques de commerce et marques déposées mentionnés sont la propriété de leurs propriétaires respectifs et sont utilisés à des fins d'identification uniquement. L'utilisation de ces noms n'implique pas l'approbation. Ce document ne constitue pas un conseil professionnel ou juridique. Pour des conseils spécifiques liés à vos besoins, veuillez consulter des professionnels qualifiés.